
-
-
小亿 管理员
发表于2020-6-2 09:58
楼主
近年来,实时大数据快速发展,并扎根于科技金融、车联网、物联网、电商、智慧城市等应用场景,创造新的价值。毋庸置疑,数据越实时价值越大,秒级甚至毫秒级的实时流式大数据计算场景层出不穷。并且当下,从数据产生到分析结果的计算,数据时效性对业务的蓬勃发展起到更至关重要的作用。
而针对当前大数据领域分析场景需求各异而导致的存储问题,亿信华辰则提供了一种新的融合数据存储方案,能融合不同架构的统一数据管理平台即PetaBase-s实时大数据平台。与早期的分布式数据库产品相比,PetaBase-s全面升级为实时大数据平台。它基于开源Hadoop框架开发,融合MPP、SQL on Hadoop、流处理等大数据技术,支持海量数据的高效储存和统一管理,为企业决策提供实时的数据支撑。
这些年,我们一直在致力于解决两个问题:
1)数据量不断快速增长,期望获取、处理和存储要求的时间越来越短;
2)用户对即时查询(hoc query)响应的要求越来越高。
在经过近一年紧张有序的开发和大量测试之后,PetaBase-s在功能和性能上都实现大幅度的提升。它就可以解决星形模型、企业数据仓库以及集成的先进分析混合模型分析等应用场景,从传统数据仓库用例到敏捷快速的实时数据智能平台,PetaBase-s实时大数据平台都很适合。
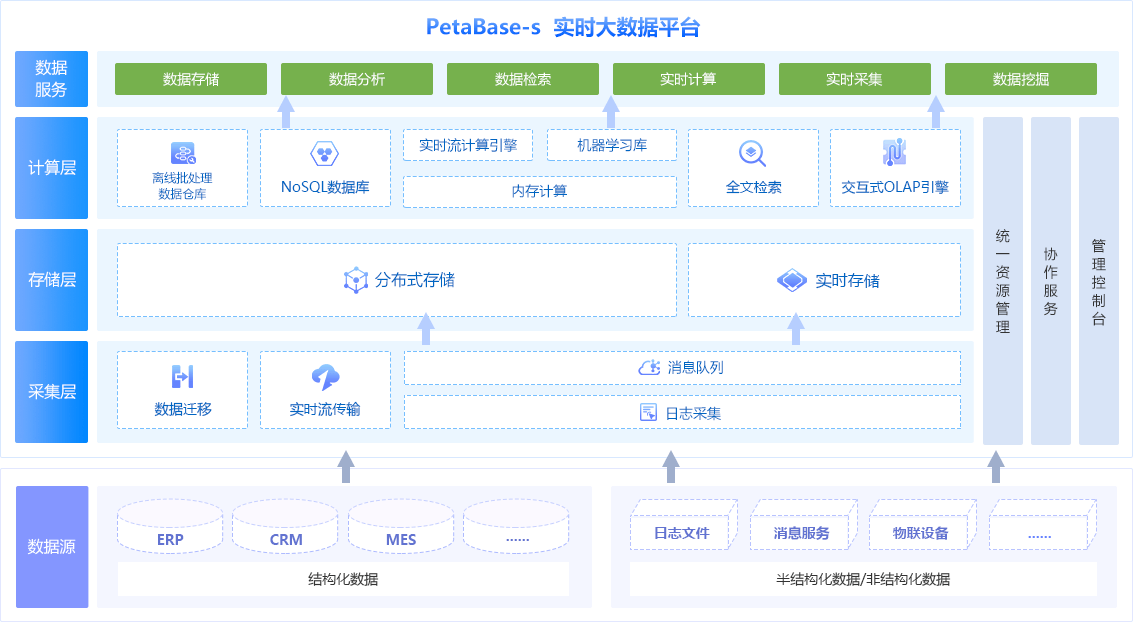
△PetaBase-s产品架构图
下面让我们一起来看看 PetaBase-s 实时大数据平台都有哪些重要特性:
早期的PetaBase分布式数据库集成了Hdfs、MapReduce、Impala、Zookeeper、Hive共计5个主流组件,主要面向海量数据集的交互式联机分析场景。
新版的PetaBase-s实时大数据平台采用了全新的企业级平台框架,以开源的Ambari作为平台统一管理工具,集成了诸多主流开源组件,数量总计近20个。其中包括:YARN(统一资源管理)、HBase(列存NoSQL数据库)、Spark(快速通用的、基于内存的、分布式的计算引擎)、Kudu(支持单条记录级别的增删改查的存储系统)、Kafka(分布式发布订阅消息系统)、Flume(分布式的海量日志采集系统)、Sqoop(关系型数据库与hdoop之间的数据ETL工具)等。
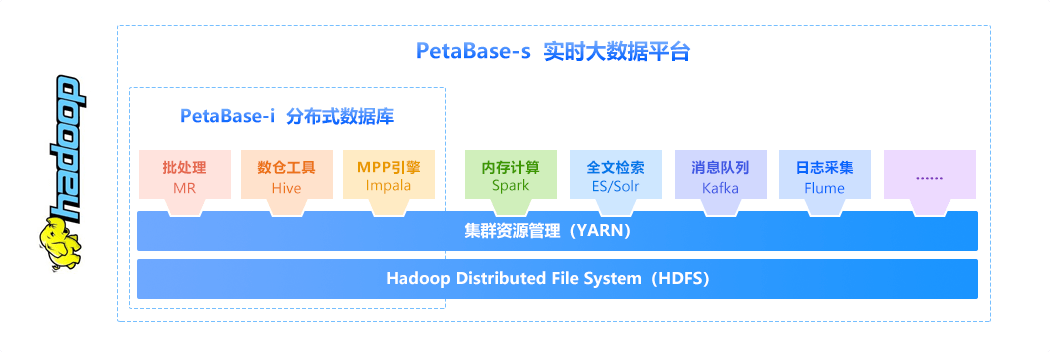
无论你需要处理的数据结构是哪种:地理空间信息、文本、自然语言或是结构化的、非结构化的图像分析,PetaBase-s都能处理。在海量的非结构化/半结构化/结构化数据集上同时进行离线计算和流式处理,还能满足高吞吐、大数据量和低时延实时处理等多方面的数据计算要求。
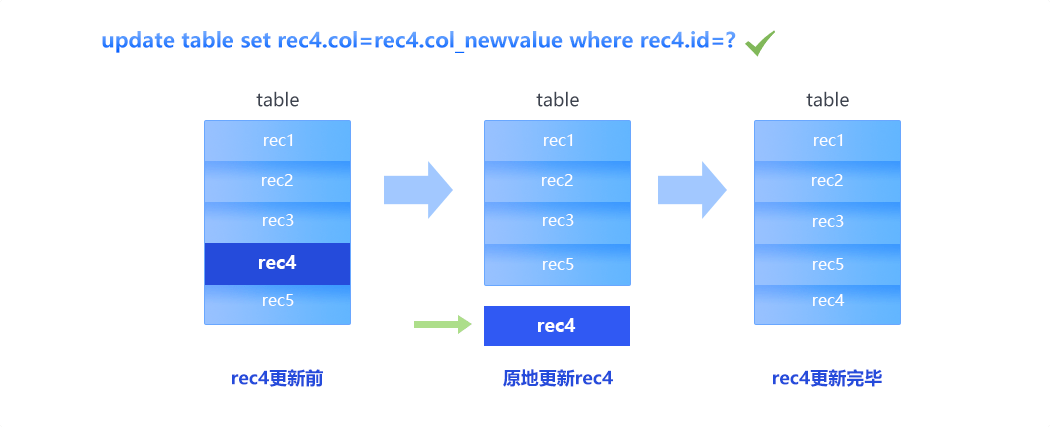
PetaBase-s实时大数据平台引入了新的存储系统——Kudu。Kudu是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。Kudu引擎不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份存储,既可以进行随机读写,也可以满足数据分析的要求。
03基于流式处理的实时计算功能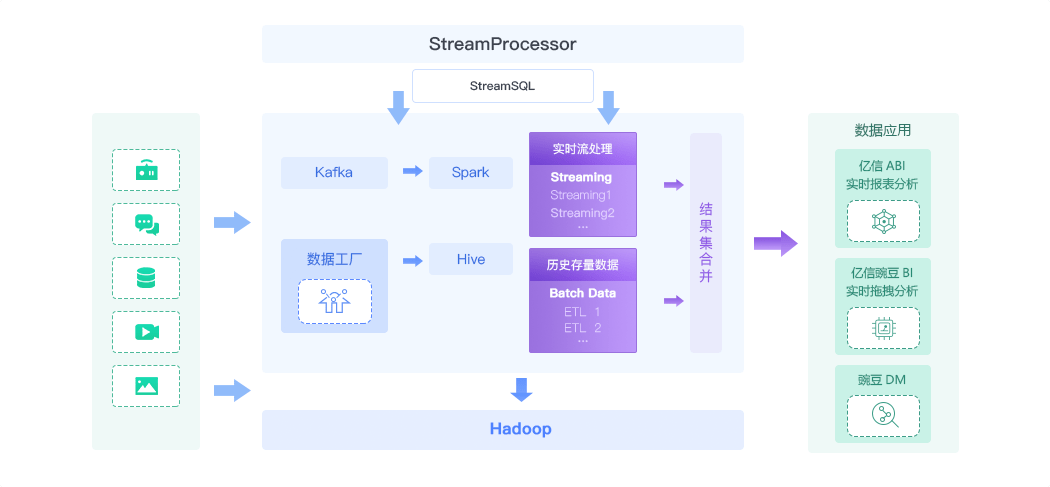
PetaBase-s实时大数据平台集成了Spark引擎,并基于Spark Streaming框架开发了一套可进行实时流计算的功能模块StreamProcessor。StreamProcessor可以实现高吞吐量的、具备容错机制的实时流数据的处理。它借助Apache Spark Engine处理微小批量的实时数据,并进行内存计算和处理优化。
另一个显著特点是用户可以用SQL书写数据处理逻辑,比如聚合、关联、过滤等。它支持Spark SQL语法,这样用户能直接使用现有的查询技术实时计算流数据。
04支持多种传输协议的数据采集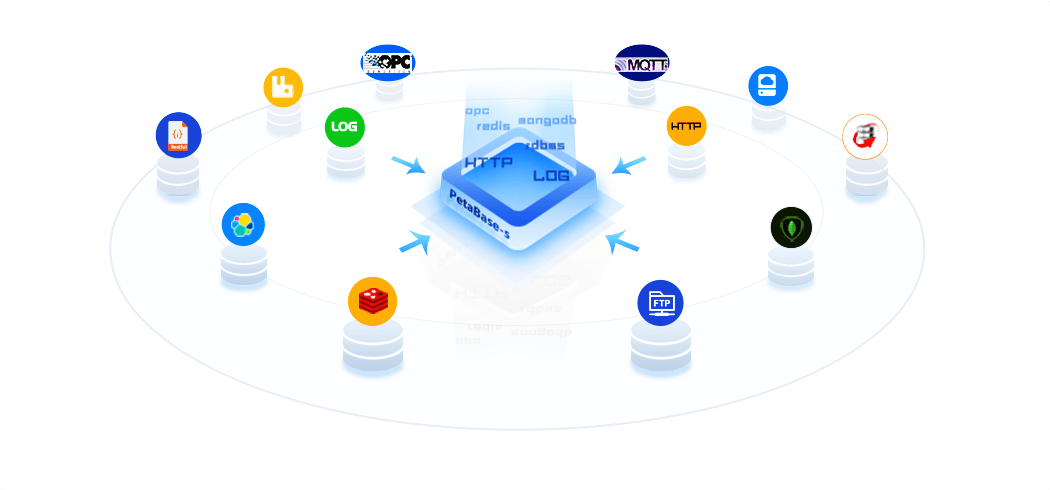
Petabase-s实时大数据平台添加了对多种数据源的接入支持,可支持OPC、MQTT等数十种传输协议,覆盖从工业物联网到传统电子交易的实时采集场景。
PetaBase还提供了基于数据库日志的采集接口,能支持Oracle、Mysql、PostgresQL、SqlServer等主流rdbms的cdc数据采集,实现联机交易类的业务数据到大数据平台的实时同步。
PetaBase-s实时大数据平台提供了一致、安全的可视化管理工具。平台向用户提供直观的Web UI以及强大的REST API,特别有利于自动化群集操作。与早期的控制台相比,新版的控制台可显著简化安装,配置和管理流程,提供集中式安全设置,增加了对群集健康的可视化监控,并具有高度可扩展性和可定制性。
除此之外,控制台还提供了对存储在PetaBase-s中的文件、数据进行访问管理的IDE。用户可以在这个IDE中编写mr,查看修改Hdfs的文件,管理Hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。
PetaBase-s实时大数据平台在存储层增加了LSM存储模型,LSM(结构化日志合并)树模型非常适合大规模在线读写。新增的存储模型对用户是非常友好的,用户甚至不需要特别关注它。建表时只需要指定表的存储属性即可使用LSM模型,之后基于该表的数据操作都和原来一样的,使用标准sql即可。基于此,LSM表可支持大并发的更改删除查询,从而提高整个系统的并发度和吞吐量。
PetaBase-s还对join(关联)操作进行了优化,减少了数据在网络交换中的传输量。结合查询优化器带来的其他优化,PetaBase的OLAP性能得到显著改进,混合负载业务尤其受益。
小结:作为具有创新性的实时大数据平台,PetaBase-s能够帮助各个行业的企业在海量的数据中洞察更多隐藏的商业价值。
在制造业,PetaBase-s能帮助企业利用工业大数据提升制造业水平,例如:产品故障诊断与预测、分析工艺流程、改进生产工艺,优化生产过程能耗等;
在金融行业,PetaBase-s在高频交易和信贷风险分析领域能发挥重大作用;
在互联网行业,PetaBase-s可以协助分析客户行为,进行商品推荐和针对性广告投放;
在电信行业,PetaBase-s可协助实现客户离网分析,及时掌握客户离网倾向,出台客户挽留措施;
在能源行业,PetaBase-s可以帮助企业掌握海量的能源生产与消耗信息,分析用户行为模式,改进基础设施运行,合理设计能源需求响应系统,确保生产安全等;
在物流行业,PetaBase-s能帮助优化物流网络,提高物流效率,降低物流成本;
在智慧城市,PetaBase-s可实现智能交通、环保监测、城市规划和智能安防
……




