
-
-
小亿 管理员
发表于2019-8-13 15:46
楼主
Hadoop大数据技术经过十来年的发展,从最初的分布式存储,解决海量数据储存的需求,到后来的Map/Reduce,满足大数据的多任务批处理,再到后来的SQL on Hadoop技术,将成熟的SQL技术应用在Hadoop上,实现海量数据交互式分析、查询,使传统数据仓库人员能轻松拥抱Hadoop大数据技术。
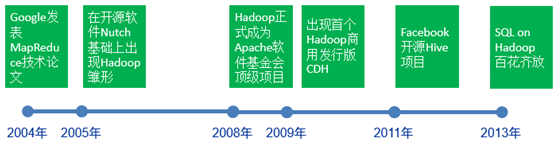
l 2004年左右,Google发表GFS文件系统和MapReduce技术论文
l 2005年初,Doug Cutting在Nutch项目代码中引入MapReduce技术,出现Hadoop雏形
l 2008年1月,Hadoop正式成为Apache软件基金会顶级项目
l 2009年3月,出现首个商业化Hadoop发行版,即CDH
l 2011年初,Facebook开源Hive项目,提供基于MapReduce技术的SQL数据仓库工具
l 2013年起,开始涌现一大批开源SQL on Hadoop技术,旨在替代或优化Hive,成为交互式即时查询引擎
大数据最大的魅力在于通过技术分析和挖掘手段带来新的商业价值。过去几年里,大数据技术得到长足的发展,许多企业已慢慢开始接受以Hadoop为基础的大数据生态系统,并将它用作其大数据分析堆栈的核心技术组件。尽管Hadoop生态系统的MapReduce组件是处理大数据的成功典范,但随着时间的推移,MapReduce技术自身并不是处理存储在Hadoop生态系统中的数据的最简单途径,企业需要一种更简单的方式来执行查询、分析、甚至要执行深度数据分析的数据,以便发掘存储在Hadoop中的所有数据的真正价值。SQL on Hadoop技术就是因应这种需求而得到发展。
SQL on Hadoop,即在Hadoop之上提供SQL方式分析数据的技术。由于传统SQL技术在帮助各类用户发掘数据的商业价值领域具有很长历史,所以SQL on Hadoop技术成为非常关键的大数据查询、分析的一个方向。SQL技术能将复杂的数据操作抽象成几个关键字(Select,Insert,Update,Delete等)类自然语言的脚本形式,易学易用,被大量现有业务系统的开发人员和DBA所掌握。因此Hadoop成为流行的大数据分析平台之后,SQL on Hadoop成为无法阻挡的趋势,现有开发人员或DBA无需太大学习门槛,即可过渡到Hadoop平台上,直接用SQL进行大数据查询和分析。
数据分析供应商和开源社区采取了各种方法实现SQL on Hadoop。在Hadoop的数据集上提供SQL支持一开始是Apache Hive,一种类似于SQL的查询引擎,它将有限的SQL方言编译到MapReduce中。Hive是目前很多企业中处理大数据、构建数据仓库最常用的解决方案,甚至在很多公司部署了Hadoop集群不是为了跑原生MapReduce程序,而是用来跑Hive SQL的查询任务。但是,由于Hive对MapReduce的过渡依赖,其每个SQL都会解析为多个MapReduce任务,而每个MapReduce任务的输出都会导致HDFS写操作,造成大量的磁盘IO,导致查询的很大延迟,其主要适用场景是数据批处理模式。
值得庆幸的是,近年来,为SQL on Hadoop提供更好的解决方案方面已取得长足进展,出现了一批数据实时交互式查询引擎。有些厂商选择从头构建分布式SQL on Hadoop引擎。另外一些厂商则采取优化Apache Hive来缩小Hive与传统SQL引擎之间的性能落差。比较典型的有Stringer/Tez、Presto、SparkSQL等。
Stinger是Hortonworks开源的一个实时类SQL即时查询系统,声称可以提升较Hive 100倍的速度。与Hive不同的是,Stinger采用Tez。所以,Hive是SQL on Map-Reduce,而Stinger是Hive on Tez。Tez的一个重要作用是优化Hive的应用场景,通过减少数据读写IO,优化查询流程使得其比Hive速度提高了很多倍。Tez与Hive主要区别是,将SQL语义抽象为Map/Reduce操作,在这两个操作的基础上提供了更丰富的接口,并减少中间结果输出到HDFS的环节。虽然Stinger对Hive进行了较多的优化与加强,Stinger总体性能还是依赖其子系统Tez的表现。
Presto是Facebook开源的一个分布式SQL查询引擎,它被设计为用来专门进行高速、实时的数据分析,并且支持标准的ANSI SQL子集。Presto的运行模型与Hive有着本质的区别。Presto引擎使用了一个定制的查询执行引擎和响应操作符来支持SQL的语法,其所有的数据处理都是在内存中进行的。Presto设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可以使用SQL进行查询。
Spark SQL是近两年发展较快的大数据处理引擎,起源于加州大学伯克利分校AMP实验室。Spark SQL是把SQL解析成RDD的transformation和action,而且通过catalyst可以自由、灵活的选择最优执行方案。但是Spark SQL是基于内存的,元数据放在内存里面,不适合作为数据仓库的一部分来使用,这也导致其在共享集群上无法高效地分配资源和调度任务。目前Spark社区把Spark SQL朝向DataFrame发展,目标是提供一个类似R的接口,把这个作为主要的发展方向。DataFrame这个功能使得Spark成为机器学习和数据科学领域不可或缺的一个组件,但是在数据仓库(ETL,交互式分析,BI查询)领域似乎不再作为其主要发展方向。
这些新兴的SQL引擎,基本上都是将SQL语句解析为有向无环图(DAG)结构,采用并行计算引擎(MPP)在Hadoop上进行大规模数据分析、查询。这类MPP架构的SQL on Hadoop查询引擎相较早期的Hive有很多优势:
l DAG vs. MapReduce:最主要的优势,查询的中间结果不写磁盘,一气呵成。
l 流水线计算:上游计算任务一出结果马上推送或者拉到下一个阶段处理,比如多表Join时前两个表有结果直接给第三个表,不像MapReduce要等两个表完全join完再给第三个表Join。
l 高效的IO:采用零拷贝、本地读技术,本地查询没有多余的消耗,充分利用磁盘。
l 线程级的并发:充分利用CPU多核多线程并发执行任务,相比之下MapReduce每个任务都要启动JVM,本身就有很大延迟,占用资源也多。
2013年我公司推出全新的SQL on Hadoop产品,PetaBase。PetaBase基于开源平台基础上开发的、具有软件著作权的国产分布式数据库系统产品。PetaBase被设计为全新的SQL on Hadoop解决方案,在开源SQL引擎之上进行了大量SQL功能增强和性能优化,性能提升数倍甚至上百倍,并且集成多项管理工具,使其更适合在Hadoop上进行大规模数据分析、检索、查询。
PetaBase是一个分布式、高性能、支持SQL的大数据并行查询引擎和数据仓库系统,提供对TB级数据交互式查询,查询结果秒级响应。
PetaBase构建于Hadoop/HDFS之上,采用分布式集群架构,具有动态线性扩展能力,具有很高的容错性、稳定性和可用性,可轻松支持PB级以上数据处理。
PetaBase支持列式存储,查询时不读取无关的数据,提升I/O性能。同时列式存储能更好的进行数据压缩,压缩率最低能到30%以下,节省大量磁盘空间。同时也支持多种Hadoop数据格式,更可轻松将现有RDBMS系统的数据导入PetaBase。
PetaBase定位于管理大规模结构化数据(从TB到PB级),是分布式的分析型数据库系统,适用于批量写操作,大规模随机查询的数据集市、数据仓库等。PetaBase是我公司大数据BI的组成部分。PetaBase已于2014年成功申请并获得国家版权局计算机软件著作权登记证书,具有源代码级的安全可控制技术,工程化的开发和优化可保证PetaBase在生产环境的实施部署。




